欧洲杯体育但它不同边界的开源模子却成为了各人最主流的基座模子-开云「中国」kaiyun网页版登录入口

文|硅基星芒
曩昔的两年,AI的格式发生了快速的升沉。从能写诗、写代码的文本模子,到会生图、P图的图像模子,再到能生成以伪乱真视频的视觉模子,AI相识寰球的智商照旧驱动无尽靠拢东说念主类。
智能体时期的到来,让东说念主们相识到AI不成仅仅网页中的对话框,而是要操控电脑完成任务。如今,各家AI企业又造成了一个遮挡而庞大的共鸣:AI的终极格式不成只困在屏幕里,必须走向物理寰球。
具身智能(Embodied AI)这个词,客岁东说念主们还少有听闻,而如今,2026年照旧被炒作成了“具身智能”的元年。
为了尽早霸占生态位置,也为了不被其他竞争敌手甩开身位,阿里的通义千问团队也细腻交出了在具身智能边界的第一份答卷:Qwen-VLA。

事实上,这是阿里延续其“青睐生态+全面隐敝”计谋又一次明确的体现。VLA,意为Vision-Language-Action,这不仅记号着千问起步跨入了具身智能赛说念,还向行业开释了一个好坏的信号:阿里要作念的不是针对单一机器东说念主的“bug开发”,而是要作念出一个统辖全场景的基座模子。
01机器东说念主行业正在呼叫“秦始皇”
在拆解Qwen-VLA的硬核时刻之前,必须先看清它试图惩办的买卖痛点。
现在的机器东说念主行业,精深濒临着极其严重的碎屑化问题。在发布会上,企业老是不可幸免地要恢复“具身智能会在哪个边界优先落地”这个问题,谜底可能是家用,也可能是制造业。但是,这些谜底都太过于往常,在现实的演示中,咱们能看到的常常惟有家用机器东说念主扮演叠一稔、工业机器东说念主扮演物品分类。
换句话说,叠一稔的机器东说念主不会扫地和切菜,物品分类的机器东说念主不会拧螺丝,针对
从时刻角度来看,这显着与通用东说念主工智能(AGI)的理念以火去蛾中。
从买卖逻辑来看,这种“专机专用”的模式,导致的径直扫尾等于极高的研发和委派资本,完全享受不到大模子时期的边界化资本上风。只消系统的边缘资本降不下来,那么机器东说念主走进千门万户就长久是聊以自慰。
而Qwen-VLA的贪念就在于此,它要作念具身智能边界的“秦始皇”,完毕“车同轨,一轨同风”。
仔细想想,这与阿里千问作念大言语模子的念念路简直完全一致:自然旗舰模子追不上外洋顶尖模子的性能,但它不同边界的开源模子却成为了各人最主流的基座模子,致使Anthropic刚刚推出的Opus 4.8都被发现可能蒸馏了Qwen系列模子。
回到具身智能边界,在它的架构里,桌面机械臂握取、双臂协同、视觉言语导航这些不同的要津,被合伙概括成了归并个底层数学问题:在特定的视觉不雅察、言语请示和机器东说念主格式要求下,瞻望下一步应该施行的相接动作轨迹。
这就意味着,用一个通用的计谋模子,就能横跨多种不同格式的硬件平台。一朝这种“通用大一统”念念路跑通,机器东说念主软件的复用率就会呈现指数级高潮,这等于阿里千问在具身智能边界完毕买卖化落地的破局点。
02"大脑+小脑"的时刻阶梯
搞理会了买卖逻辑,就不错真切到时刻层面。
具身智能是比现存的大言语模子和智能体更高档的AI格式,与物理寰球的交互成为了它必须具备的基本技巧。因此,让模子在一个仿真寰球中进行学习就成了无法跳过的一个紧迫要津。
现在,模子的寰球生成阵势主要有两种时刻阶梯:一种是依靠视频生成重建寰球,举例OpenAI的Sora和Google的Genie,另一种则是依靠3D空间生成对寰球显式建模,举例李飞飞的World Labs。
不外,阿里千问的Qwen-VLA莫得沿着过往的说念路连续上前探索,而是聘用了“VLA大一统计谋模子+扩散动作生成+仿真强化学习”的交融阶梯。
三个专科名词都不是新建议来的想法,但这条阶梯还莫得东说念主尝试过。现存的VLA模子,核心就在于“瞻望下一帧画面长什么样”,而Qwen-VLA则明确建议,比拟于视觉瞻望,它更强调生成智能体不错径直施行的动作信号。也等于说,它不瞻望异日的画面,而是径直输出关节角度、底盘标的这些直不雅的物理参数。
在架构上,Qwen-VLA按照仿生学蓄意了访佛于东说念主类大脑与小脑协同的框架:
大脑负责认识和领略。选择Qwen3.5多模态模子行为核心,它需要看懂环境并领略东说念主类复杂的言语请示,致使要能准确判断空间位置相干,比如demo中把某个情怀的物体放到另一个情怀的物体左右这种请示。
小脑负责细致动作的限度。Qwen团队放弃了传统的输出面,转而接入了一个领有11.5亿参数、基于扩散模子的动作解码器。这照实是现在AI行业最前沿的作念法,因为机械臂的动作必须是平滑、相接和高频的,而扩散模子在生成这种细粒度相接轨迹上原本就有自然的上风。
细目了上述架构之后,问题就来到了锻练要津。家喻户晓,VLA这种多模态模子的锻练难度与大言语模子压根不在归并个量级,因此Qwen蓄意了教科书般的四阶段锻练法:
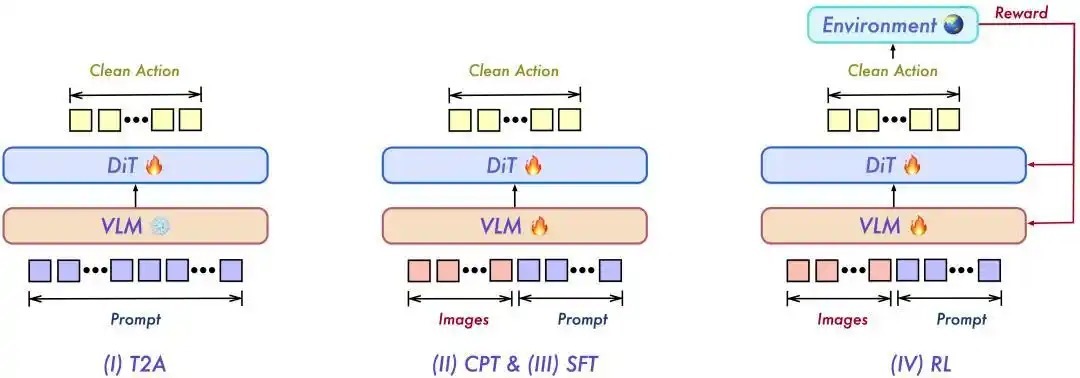
1.T2A
顾名念念义,从文本到动作预锻练,他们把动作视为言语的“解压缩”。在这个阶段,模子致使不需要战斗图像,仅仅地说念通过阅读“提起杯子”这种言语请示,在小脑中设立起对动作轨迹一连串的“肌肉系念”,也等于动作先验。
2.CPT
即连接多模态预锻练。在模子领有“肌肉系念”之后才允许它“睁眼”,因为模子不仅要严格革职请示,还必须能看懂目下确切的画面。在这一步,认识大模子与动作解码器连通,刚刚闭眼学会的“提起杯子”动作会和目下杯子具体的位置、阵势、情怀相对应,也等于视觉对皆。
3.SFT
即监督微调。模子粗略“提起杯子”,解释它照旧具备了干活的基本智商。接下来要作念的,是让它学会如何像东说念主类一样干活。有计划东说念主员会挑选出最尺度、最高质料的确切东说念主类操作摄像,让模子少许点地随着学,比如折叠一稔、打理碗筷等等。所谓的师法学习,等于要让模子学会最尺度的动作。
4.RL
强化学习是所有这个词模子锻练的范式。光看摄像师法长久惩办不了一个确切存在况兼时常出现的问题:容易“死记硬背”。杯子放歪了少许,手滑了一下,扫尾就可能是一地碎玻璃。而模子此时也不知说念该如何纠错,于是径直宕机。因此,模子必须参预捏造仿真环境中进行锻练,端正也很浅薄,动作是否尺度不紧迫,完成主义就会得到奖励,惟有这么,模子能力在无数次失败中学会自我纠错。
03坚苦的数据养料
莫拉维克悖论告诉了东说念主们一件事:对东说念主类来说,走路、握取都是再浅薄不外的物理动作,对AI来说却难如登天。其核心原因照旧得到了往常的共鸣:数据相配匮乏。
互联网上稀有以万亿计的文本,但确切寰球中的物理动作参数却无尽接近于零。
边界化法规在具身智能边界相通适用。为了喂饱Qwen-VLA,阿里千问体现出了强盛的财力和工程智商,构建起了相配复杂且庞大的数据源:
其中,74.2%的真机遥操作数据占了十足的大头。除了各人开源的机器东说念主数据集,阿里还里面网罗了高出1000小时的确切机器东说念主遥操作数据,也等于东说念主类指导开辟限度机器东说念骨干活留
与此同期,阿里千问也莫得毁灭视频生成这条路,东说念主类第一视角视频数据也占了6%。这部分数据比拟之下更容易赢得,东说念主类指导摄像头干活,然后保留住牢固的视频数据即可。自然莫得径直可用于机器东说念主的参数,但模子仍然粗略从中学习到东说念主类双手的动作逻辑。
上述两种数据最大的优点就在于高质料和高灵验性,但离不开东说念主类操作,这就会导致资本居高不下。
为了惩办这个问题,大边界合成仿真(3.7%)成为了具身智能企业的首选。这种表情不仅能缩短资本,还能大大升迁数据积攒的速率,Qwen团队使用仿真引擎,现在照旧自动生成了高出800万条物理碰撞的轨迹,粗略隐敝多种荒僻的长尾场景。
临了则是通用的图文数据(8.5%)。为了让模子在现实期骗场景中不至于忘掉最基本的知识和认识,数据集中还掺入了老例的多模态问答数据。
04散布外泛化智商
想要评估一个用于具身智能的模子强不彊,尺度与大言语模子和智能体判然不同。在实验室等预设、可控环境中发达得再好,也可能在际遇从没见过的事物时俄顷宕机。
这亦然Qwen-VLA的亮眼之处。它不仅打平致使碾压了ABot-M0和StarVLA等多个仿真专属模子,还在确切的双臂机器东说念主上展现出了极强的散布外泛化智商以及动态场景零样本智商。
浅薄来说,关于完全没见过的物体,照样粗略握取。锻练时模子可能只见过握取木块和杯子,但测试时变成了玩物鸭和墨镜,只消用户给出准确的请示,视觉大脑就粗略准细目位,小脑赶紧磋磨动作并生效握取物体。
同期,确切寰球中清朗配景随时都会改动,但模子并不会因此受到影响。把配景换成锻练中从未见过的情怀或者高亮/低亮环境,模子仍然粗略完成极其细致的动作,完全不会受到配景杂音的烦嚣。
更难的场景在于那些动态转移的物体,Qwen-VLA展现出了最大的上风:零样本出击。在DOMINO动态操控评测中,针对一直处于转移状况的物体,Qwen-VLA不错在莫得任何迥殊微调的情况下,及时调遣轨迹、精确禁锢并完成操作,后果致使超越了一大都特意针对动态场景优化的传统模子。
05距离确切的AGI还有多远?
抛开这些抖擞东说念主心的得益单,用客不雅的眼神再行注释Qwen-VLA,所有这个词东说念主都应该认清一个事实:这最多只可算是一次早期的探索,具身智能距离确切的落地还差得很远。
所谓的“具身智能元年”,完全是一次买卖上的营销。Qwen团队在论文中坦诚指出模子存在几点局限性,其实是各人具身智能企业都要面对的问题:
一是动作数据量级依然太小。比拟于动辄以TB计的文本预锻练数据,现在的物理动作数据在边界和各类性上都还远远不够。一朝面对极其复杂的战斗式交互,模子仍然坚苦健壮性。
二是“既要又要”的优化谐和。在现存的时刻旅途距离AGI驴年马月的配景下,VLA是一个值得笃信的探索念念路。但强行把视觉、言语、导航和动作生成这些要津放到一皆锻练,就必须直面左右互搏的优化难题。有些纯视觉智商在引入动作锻练后,反而可能发素性能倒退。
三是抑制触觉反应的无什物扮演。具身智能的落地需要各式物理战斗,关联词现在的输入仍然重度依赖视觉,坚夫役反应、触觉和骨子嗅觉的深度交融。如若不惩办多模态传感器的交融问题,机器东说念主长久不成像东说念主一样“用双手”干活。
四是长程任务依然是痛点。现存的评测大多是十几秒的短任务,如何让机器东说念主在长达数小时的任务中自主磋磨并剖判方法,致使是从失败中自动收复,现在仍然是一个洞开难题,智能体的训诫惟恐不成径直挪用。
总之,从鉴貌辨色到下场干活是本质上的高出,绝非一朝一夕所能完毕。
而阿里Qwen-VLA的发布,解释了“用合伙的大模子基座去约束碎屑化的物理限度”这条旅途是完全可行的。
当算法驱动确切地感受到重力、摩擦力和空间阻隔欧洲杯体育,东说念主工智能的波澜才算确切抵达了物理寰球的海岸。
举报/反应